腾讯云计算加速套件TACO Kit在裸金属服务器上部署 TensorFlow 分布式训练集群
操作场景
本文介绍如何基于裸金属服务器搭建 Tensorflow+Taco Train 分布式训练集群。
操作步骤
购买实例
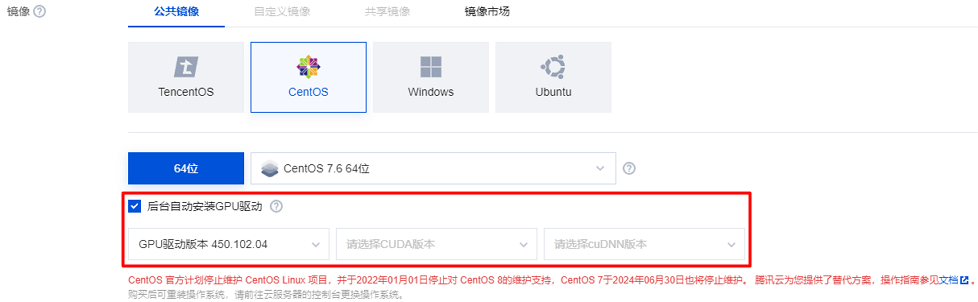
购买实例,其中实例、存储及镜像请参考以下信息选择,其余配置请参考 通过购买页创建实例 按需选择。实例:选择 GPU 型 HCCG5v、GPU 型 HCCG5vm 或 GPU 型 HCCPNV4h。系统盘:配置容量不小于50GB的云硬盘。您也可在创建实例后使用文件存储,详情参见 在 Linux 客户端上使用 CFS 文件系统。镜像:建议选择公共镜像,公共镜像当中已安装 RDMA 网卡驱动,且支持自动安装 GPU 驱动。若您选择自定义镜像,则需要自行安装 RDMA 网卡驱动和 GPU 驱动,请通过 联系我们 获取腾讯云售后支持。操作系统请使用 CentOS 7.6。若您选择公共镜像,则请勾选“后台自动安装GPU驱动”,实例将在系统启动后预装对应版本驱动。如下图所示:
安装 nv_peer_mem(可选)
多机通信的过程中,GPU 显存中的数据需要首先拷贝到内存中,然后通过网卡发出。通过 GPU Direct RDMA 协议,可利用 GPU 和网卡直接通过 PCIe 进行 Peer2Peer 的数据交换这条更快速的路径,无需借助内存来进行数据的传递。如需使用 GDR 进行数据传输,请在实例中执行以下命令,安装如下驱动。
git clone https://github.com/Mellanox/nv_peer_memory.gitcd ./nv_peer_memory/ && git checkout 1.0-9make && insmod ./nv_peer_mem.ko// 如果服务器发生了重启,nv_peer_mem驱动需要重新insmod
安装 docker 和 nvidia docker
1. 参见 使用标准登录方式登录 Linux 实例,登录实例。2. 执行以下命令,安装 docker。
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-docker.sh | sudo bash
若您无法通过该命令安装,请尝试多次执行命令,或参考 Docker 官方文档 Install Docker Engine 进行安装。
本文以 CentOS 为例,安装成功后,返回结果如下图所示:
3. 执行以下命令,安装 nvidia-docker2。
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-nvidia-docker2.sh | sudo bash
若您无法通过该命令安装,请尝试多次执行命令,或参考 NVIDIA 官方文档 Installation Guide & mdash 进行安装。
本文以 CentOS 为例,安装成功后,返回结果如下图所示:
下载 docker 镜像
执行以下命令,下载 docker 镜像。
docker pull ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-bm-0.4.2
该镜像包含的软件版本信息如下:OS:18.04.5ofed: MLNX_OFED_LINUX-5.1-2.5.8.0python:3.6.9cuda toolkits:V11.2.152cudnn library:8.1.1nccl library:2.8.4tencent-lightcc :3.1.1ttensorflow:1.15.5其中:LightCC 是腾讯云提供的基于 Horovod 深度定制优化的通信组件,完全兼容 Horovod API,不需要任何业务适配。ttensorflow 是腾讯云基于开源 tensorflow 1.15.5添加了 CUDA 11的支持,同时集成了 TFRA,用来支持动态 embedding 的特性。如需了解更多信息,请参见 产品概述。
启动 docker 镜像
执行以下命令,启动 docker 镜像。
docker run -itd --rm --gpus all --shm-size=32g --ulimit memlock=-1 --ulimit stack=67108864 --net=host --privileged ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-bm-0.4.2
注意--privileged 选项使容器能够访问主机上的 RDMA 设备。
分布式训练 benchmark 测试
说明docker 镜像中的文件 /mnt/tensorflow_synthetic_benchmark.py 来自 horovod example。展开全部单卡执行以下命令,进行测试。
/usr/local/openmpi/bin/mpirun -np 1 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL_IB_GID_INDEX=3 -x NCCL_NET_GDR_LEVEL=0 -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl_tcp_if_include bond0 -mca btl ^openib python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
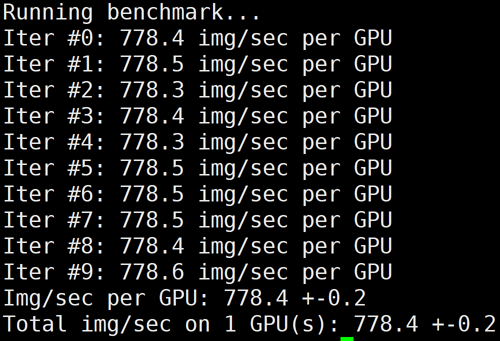
下图为 HCCPNV4h/A100的单卡 benchmark 结果:
单机多卡执行以下命令,进行测试。
/usr/local/openmpi/bin/mpirun -np 8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL_IB_GID_INDEX=3 -x NCCL_NET_GDR_LEVEL=0 -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl_tcp_if_include bond0 -mca btl ^openib python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
下图为 HCCPNV4h/A100的8卡 benchmark 结果:

多机多卡1. 参考 购买实例 – 启动 docker 镜像 步骤,购买和配置多台训练机器。2. 配置多台服务器 docker 间相互免密访问,详情请参见 配置容器 SSH 免密访问。3. 执行以下命令,使用 TACO Train 进行多机训练加速。
/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL_IB_GID_INDEX=3 -x NCCL_NET_GDR_LEVEL=0 -x HOROVOD_FUSION_THRESHOLD=0 -x HOROVOD_CYCLE_TIME=0 -x LIGHT_INTRA_SIZE=8 -x LIGHT_2D_ALLREDUCE=1 -x LIGHT_TOPK_ALLREDUCE=1 -x LIGHT_TOPK_THRESHOLD=2097152 -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl_tcp_if_include bond0 -mca btl ^openib python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
下图为 HCCPNV4h/A100 2机16卡 benchmark 结果:
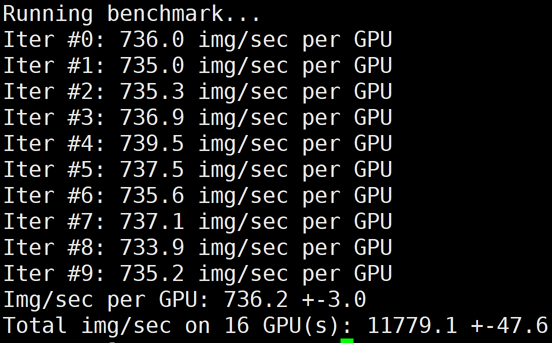
LightCC 的环境变量说明如下表:
| 环境变量 | 默认值 | 说明 |
| LIGHT_2D_ALLREDUCE | 0 | 是否使用2D-Allreduce 算法 |
| LIGHT_INTRA_SIZE | 8 | 2D-Allreduce 组内 GPU 数 |
| LIGHT_HIERARCHICAL_THRESHOLD | 1073741824 | 2D-Allreduce 的阈值,单位是字节,小于等于该阈值的数据才使用2D-Allreduce |
| LIGHT_TOPK_ALLREDUCE | 0 | 是否使用 TOPK 压缩通信 |
| LIGHT_TOPK_RATIO | 0.01 | 使用 TOPK 压缩的比例 |
| LIGHT_TOPK_THRESHOLD | 1048576 | TOPK 压缩的阈值,单位是字节,大于等于该阈值的数据才使用 TOPK 压缩通信 |
| LIGHT_TOPK_FP16 | 0 | 压缩通信的 value 是否转成 FP16 |
4. 执行以下命令,关闭 TACO LightCC 加速进行测试。
# 去掉LIGHT_xx的环境变量,即可使用Horovod进行多机Allreduce/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL_IB_GID_INDEX=3 -x NCCL_NET_GDR_LEVEL=0 -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl_tcp_if_include bond0 -mca btl ^openib python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
下图为 HCCPNV4h/A100 2机16卡,关闭 LightCC 之后的 benchmark 结果:
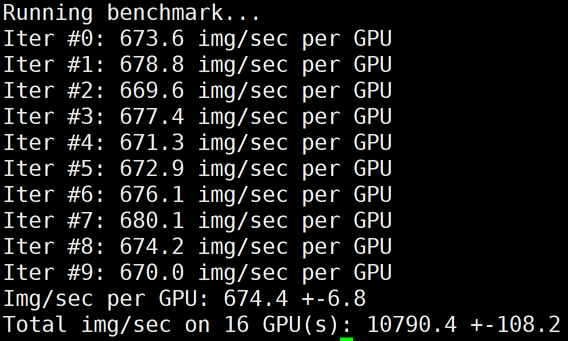
多机多卡 GDR执行以下命令,使用 GDR 进行测试。注意:使用 GDR 需安装 nv_peer_mem,详情请参见 安装 nv_peer_mem。
/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x NCCL_IB_DISABLE=0 -x NCCL_SOCKET_IFNAME=bond0 -x NCCL_IB_GID_INDEX=3 -x NCCL_NET_GDR_LEVEL=2 -x HOROVOD_FUSION_THRESHOLD=0 -x HOROVOD_CYCLE_TIME=0 -x LIGHT_INTRA_SIZE=8 -x LIGHT_2D_ALLREDUCE=1 -x LIGHT_TOPK_ALLREDUCE=1 -x LIGHT_TOPK_THRESHOLD=2097152 -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl_tcp_if_include bond0 -mca btl ^openib python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
GDR 通常在大模型或者集群规模较大时有显著的加速效果,测试结果如下图所示:
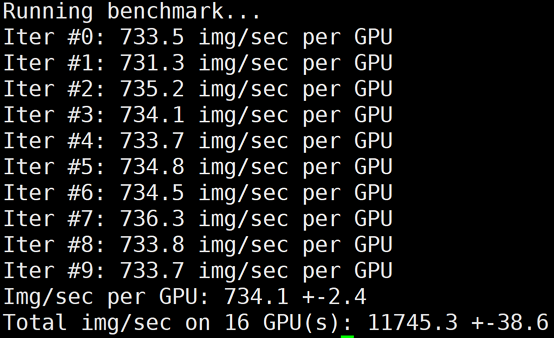
总结
本文使用环境及测试数据如下:
| 机器:HCCPNV4h(A100 * 8)+ 100G RDMA + 25G VPC 容器:ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-bm-0.4.2网络模型:ResNet50Batch:256数据:synthetic data | |
|
|
|
|
| 机型 | #GPUs | Horovod+RDMA | |
LightCC+RDMA | |
| |
|
性能(img/sec) | 线性加速比 | 性能(img/sec) | 线性加速比 |
| HCCPNV4h A100 | 1 | 778 | – | 778 | – |
| |
8 | 6104 | 98.07% | 6104 | 98.07% |
| |
16 | 10790 | 86.68% | 11779 | 94.63% |
说明如下:对于 HCCPNV4h/A100,相比开源方案,2机16卡通过 LightCC 可以将线性加速比从86.68%提升到94.63%。上述 benchmark 也支持除 ResNet50之外的其他模型,ModelName 请参考 Keras Applications。上述 docker 镜像仅用于 demo,若您需使用自己的 docker 开发环境,请参考 容器安装用户态 RDMA 驱动 安装网卡驱动。如需特定 OS/python/CUDA/tensorflow 版本的 LightCC 加速组件,请通过 联系我们 联系腾讯云售后获取。
官网1折活动,限时活动,即将结束,速速收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利。同意关联立享优惠
- 0人点赞 -
相关推荐

腾讯云实时互动教育版产品动态_音视频解决方案_同尘科技
腾讯云多人音视频房间SDK多人音视频房间 SDK 2.0版本发布和推荐升级公告_音视频解决方案_同尘科技
腾讯云多人音视频房间SDKSDK2.0版本升级指引_音视频解决方案_同尘科技
暂无评论,你要说点什么吗?